Case Studies
Case Study 1: Freeze Site Before Translation begins
In this example, the client has declined to use a staging server, as well as declining to halt content updates for the duration of the initial translation. They do, however, insist that bleedthrough must not occur at any point in the translation process. This results in a continuously changing source that makes it nearly impossible to achieve 100% translation.
In this case, the solution is to enable the Origin Snapshot, and populate it with a Scan before the first round of translation commences. This creates what is effectively a static snapshot of the site, which remains the same regardless of the updates the client makes in the meantime, providing a stable environment for the translation and review processes.
By using an Origin Snapshot to serve the translated sites, they are decoupled from the original, and content updates there will not be reflected in the translations.
However, source content will accumulate in the meantime, and once the snapshot is purged, bleedthrough will occur! To counter this, the second scenario can be enacted.
Case Study 2: Decoupling Content Update from Ingestion and Publishing
For this example, the client has declined to use a staging server to allow you to ingest the content ahead of publishing for translation. They did, however, agree to notify you once new content is published, and have acknowledged that this will cause the translated sites to lag behind the original until the translations (and possibly reviews) are completed. Alternatively, coupling into the previous scenario, the initial translations are in place, but the source site has moved ahead in the meantime, with the translated site being served by the initial Origin Snapshot.
Once the initial translations are completed, the snapshots are set up according to the image below:
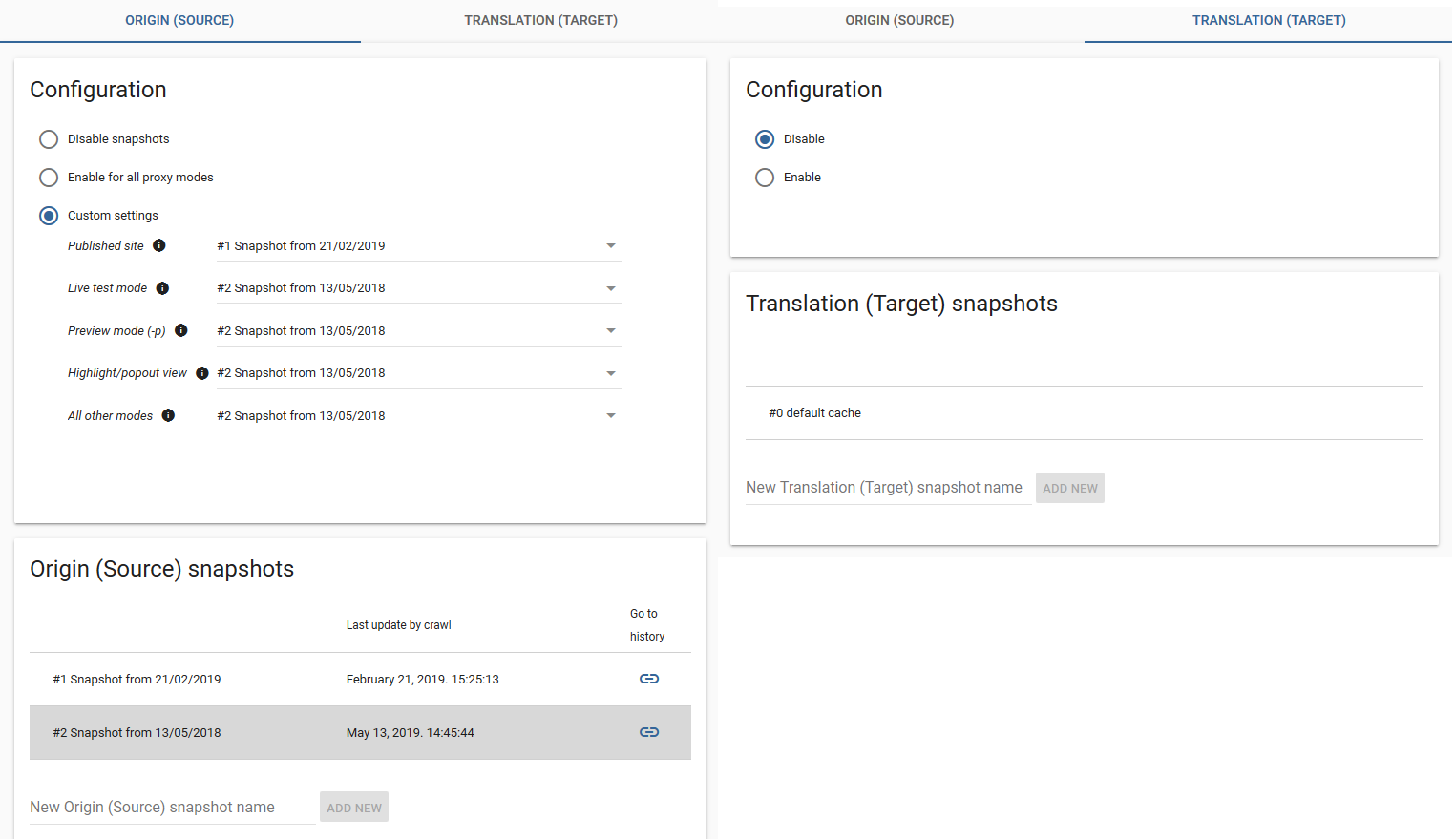
By driving the published site from a separate snapshot entity, you gain the ability to decouple the content ingestion cycle from the translation and update cycles.
From this point on, the published site will not reflect any updates until the assigned entity is refreshed. By specifying the update snapshot in the Crawl Wizard, you write the server responses into the newly created snapshot, which will drive the Preview and Highlight modes, allowing you to conduct the translations and ICR using the new content. Once the client signs off on the translations, you simply switch the Origin Snapshot entities being used (and purge the Translation Snapshot, if in use).
Once translations and reviews are completed, simply re-assign the snapshot entities to promote the new content to the translated “Production”
At this point, the previously-live snapshot is freed up for purging and re-building in the next update cycle. Thus, at the next crawl, the default would be selected to receive the updates, leaving the other entity untouched.
To facilitate this process, you can set up a Round-Robin Crawl. These are Crawls that are done periodically, writing content into a different Snapshot every time (i.e. it writes first into #1 then next month into #2 and into #3 on the third. On the fourth month, it starts the circle again by writing into #1). To set it up, you first have to ensure that you have at least two Origin Snapshots (they can be empty at this point). Then, you should set up a Scan using the Crawl Wizard. On step 4, first navigate to the Recurrence tab, select the repeat interval and tick the “Use different Origin Snapshots for every crawl” option. Then, you must select the Origin Snapshots tab and select which ones to use. Once all of this is in place, you can review your settings and start the crawl.