Pages list
The page list lets you keep track of the various URLs that are (or were) seen by the proxy. Aside from the overview of and direct access to content on the individual pages, the page list also allows you to visit the various proxy preview domains, fine-tune inclusion/exclusion settings and check the translation progress of individual pages.
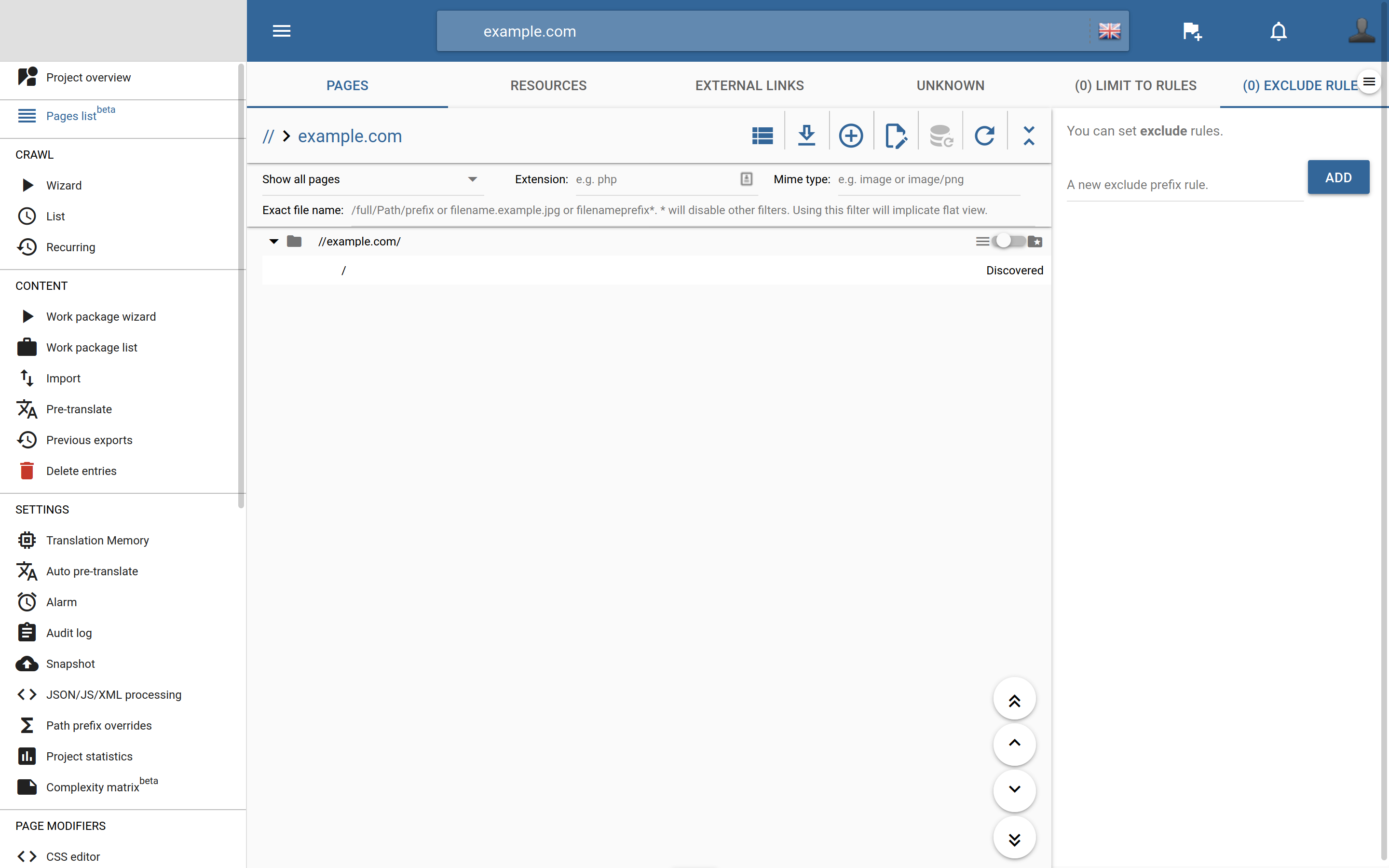
This menu has two main parts visible when you first open it: the “Pages, resources, external links & unknown” pane and the include/exclude rules.
Also notice the language selector on the right of the project selector. Information in the translation progress bars will refer to the selected language, and both the List and Highlight Views will open for the selected target language. The same is true for the various types of Preview links.
Make sure that you have selected a target language to gain access to many powerful features in the page list. If you do not (or there is no target language on the project at all), neither the Workbench links, nor the Previews will be available, and most of the context menu options will be greyed out.
Pages, resources, external links & unknown
Here you can see all the items that the proxy is aware of (either because of crawls or user visits). They are split into 4 categories: pages, resources, external links and unknown.
Pages are links that contain translatable content. By default, these are the HTML pages on the project but you can move others (like JSONs) from the other sections.
Resources are images, PDFs and similar that the proxy can’t automatically extract content from. However, you may want to localise these by uploading a replacement.
External links (like those pointing to YouTube videos) can be replaced (e.g. if the video is available in the target language). Note that if you are working on a project for www.example.com, blog.example.com is considered external to it
There should be no entries under Unknown but if you can’t find something you may want to check it here.
Above the list itself, there are multiple actions you can do and filters. These are:
Switch to flat/folder view: Switch between the flat view (default for resources), which is just a list of URLs similar to the old Dashboard and the folder view (default for pages) that allows you to see the pages as if they were files on your computer. External links are only available in flat view so this option is hidden for them.
Show/hide preview (only for resources): Whether to load the images or just display their filename. If you have a slow connection or a data cap, we recommend hiding these.
Export URL list: Create a CSV or Excel export of the current list. You can filter the links by translation state or free text search. Due to Excel’s limitation on the number of lines per sheet, a CSV export is recommended for large-scale projects.
Add new: Run a page-specific crawl. Use it to add new pages or refresh already extracted pages in a “surgical” fashion. HTTPS URLs are added using fully qualified URLs. If you specify the pathname only, such as
/about-us.html, the proxy will default to requesting the page over HTTP. The same applies to any resource that is available via both HTTP and HTTPS: add both URLs to ensure that you have all possible versions of the page or resource.Mass page exclusion: Enter a list of URLs that you wish to exclude. Use this when you can’t add an exclusion rule. You also have the option to “un-exclude” aka include some pages again.
Update translation progress: Updates the bars showing the progess. This can take from a few seconds to a few minutes of time to finish, depending on the amount of content to be aggregated.
Reload: Reloads the list of pages.
Show/hide filters: Controls the filters discussed below.
Note that some of them are only available for either of the types.
Below these actions, you can search by file name or filter pages, resources and external links
By their inclusion status,
Their extension (especially useful for resources)
Their MIME type. Note that the extension of a file isn’t necessarily the same as its mime type.
Page details and options
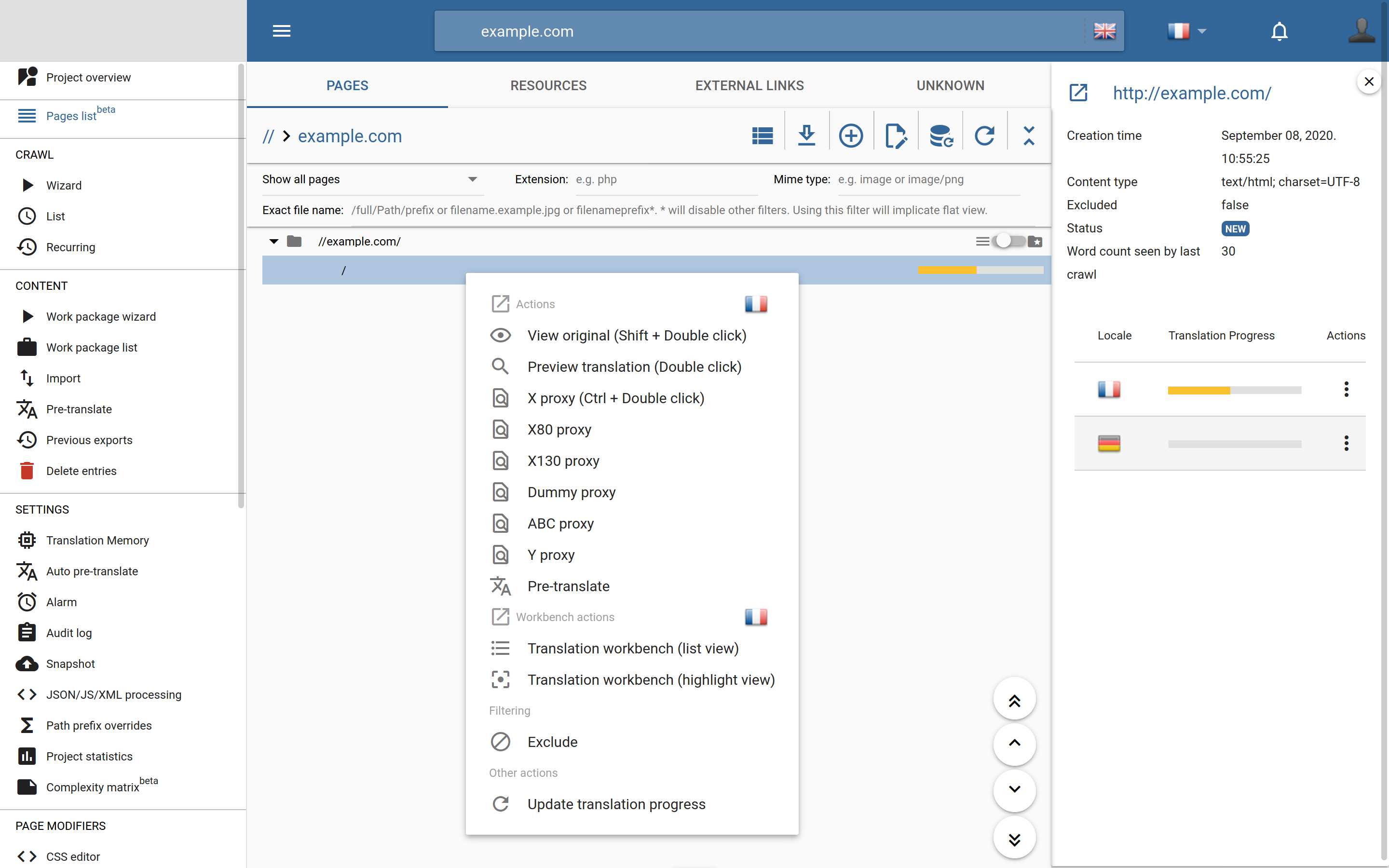
Clicking on a page in the list reveals further information about it on the right side. Here you can see basic details such as the time it was first seen, its content type, status and word count. You can also see the translation progress for all languages (the progress of the currently selected language is displayed at all times).
There are a number of states that a page can be in throughout the lifetime of a project:
Unvisited: Indicates pages that were already seen in the source of another page, added to the list, but for one reason or another, not visited by a crawler. For example, if you run a Discovery with a page limit of 8 and allow it to collect new URLs at the same time, it will likely visit the landing page, “/”. The landing page is likely contain many references to various pages on the same domain. The Discovery will exit after 8 pages, but also add the rest as “Unvisited”.
Discovered: Pages that were included in a word count previously are said to be Discovered. The content on them is accounted for in at least one of the word count statistics, but the translatable content has not been extracted for translation yet.
NEW: “New” in this part refers to the fact that the page’s content is extracted and in a “pristine” state: no entries on it have been translated yet. It is usual to find pages in “NEW” state right after the first content extraction crawl (when a project has all the content ready for translation, but no translations have been provided yet).
Progress bar: will be shown when a non-zero percentage of the entries that the given page refers to have been translated. Note that due to automatic propagation, translating one entry can influence the progress bars of multiple pages). Hovering over the progress bar will show more specific numbers in the tooltip, but progress is also color-coded as follows (end value decimal places are omitted):
progress < 30%- redprogress < 60%- yellowprogress < 100%- greenprogress = 100%- blue
You can right-click on a page to display page-specific actions. Again, depending on context, some of them may not be available.
View original: Load the original page in a new tab.
Preview translation: Load the Preview. Use this mode to ensure that everything is translated.
X proxy: In this mode, all content that the proxy can pick up is replaced with
xs. This mode can be used to find content inserted via JavaScript and such because these won’t bexed out.X80 & X130 proxies: These mode behave like the x proxy but simulate different lengths of text by shortening or expanding it to 80% and 130% respectively. This mode is useful to detect layout anomalies that arise from text expansion.
Dummy proxy: Displays the page as received from the original server. Use this to debug issues where you suspect the original server treats the proxy differently than other users (e.g. the firewall blocks it by IP).
ABC proxy: A special, improved variant of the X proxy. In this mode, text is replaced with either
x,a,borcdepending on its status.x: Content that can be translated but wasn’t scanned yet.a: No translation is available yet but the segment was scanned and is ready for translation.b: The translation is the same as the source or it was translated but the translation was removed.c: The segment is translated.
We hope to further improve this mode. If you have any suggestion, please don’t hesitate to contact support.
Pre-translate: Brings up the pre-translate dialog for this specific page.
Translation workbench (list or highlight view): Brings up the Workbench which is an online computer assisted translation tool. List view is similar to what you’d find when using MemoQ. A list of segments and their translations side by side wiht suggestions from the TM on the right and an editor near the bottom. Highlight view is similar but instead of the segment list, the page is loaded and you can hover on the text that you need to translate. This allows in-context translation.
Exclude/select: Allows you to mark the specific page as translatable or excluded.
Update translation progress: You can update this progress for individual pages if you wish.
Mark for replacement: Once an image is marked as translatable, a new Manage translations button becomes available. After clicking it, you can upload localised versions of the image that will be displayed on the translated sites.
Add to resources for link replacement: Allows you to move an external link to resources so that you can process it as such.
Page deletion
A project, especially one with few inclusion/exclusion rules or one that uses URLs with many query parameters can over time accrue many pages in the page list. Page deletion is now available as a user feature.
By clicking on the Trashcan icon on the Pages list page, a pop-up window shows up.
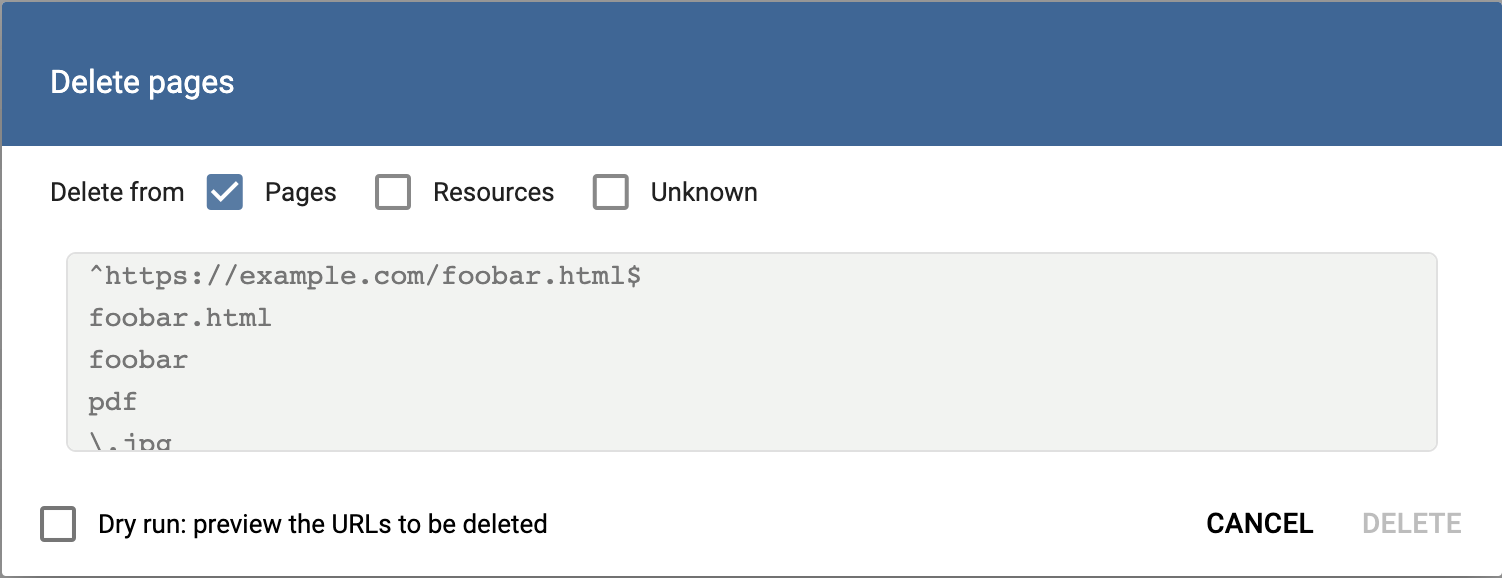
There is an option to select what kind of content you want to delete, pages, resources, and unknown. The default option is pages, which will only look for pages matching the regex.
The most important part of the process is defining the right regular expression (regex) for your needs. (You can find an online regex tester here.)
Once you have your regular expression ready, by checking the checkbox Dry run: preview the URLs to be deleted and clickick the Preview button, you can run a preview of the pages that are about to be deleted to avoid incidents like deleting pages by mistake, and you can also check if the pattern matching found each and every page you intend to get rid of.
Once you made sure you want to delete all the pages in the preview, just uncheck the checkbox Dry run: preview the URLs to be deleted and hit the Delete button.
You will get notifications through the process. Once the page deletion is ready, you can refresh the pages list, and the desired pages should be removed.
Deleting pages from the project does not prevent them from being re-added, at least not in itself (for that, additional configuration is needed that actually addresses the root cause of the page being added, for example ignoring query parameters or excluding pages from the Crawls).
Include & exclude rules
Inclusion rules let you set the scope of translation, that is, the list of pages that the crawler is allowed to visit. You can enter the prefixes that you wish to limit the scope to (or exclude from it). You can also exclude individual pages should you see fit.
The Dashboard has a number of features that support inclusion/exclusion prefixes, such as Auto-pretranslation or Work packages. However, the rules you specify here are special and powerful: they have influence over the entire project. An excluded page will stay untranslated over any proxy domains (both Preview and Live), and excluded pages are ignored by the crawler.
NOTE: You can enable/disable the application of rules using the checkbox associated with them or you can delete them completely.
Rule Application
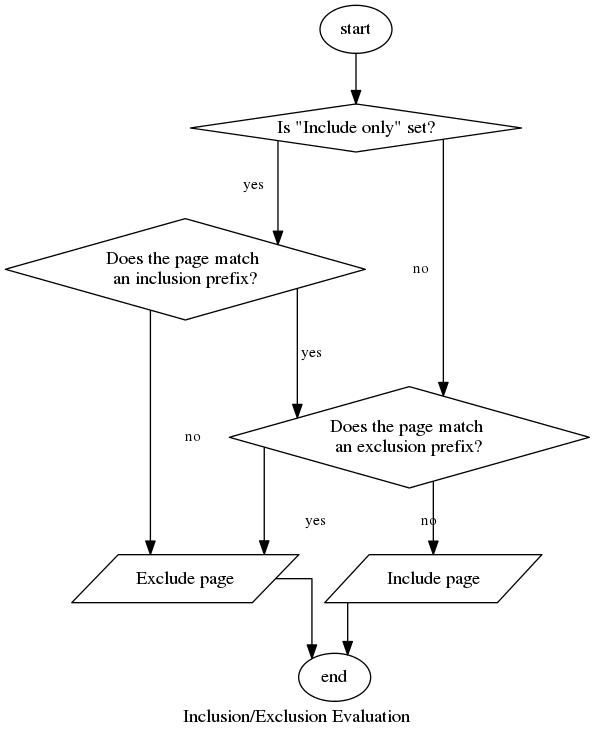
Whenever the proxy comes across a page in an affected context (crawling, serving, translating, etc.), it will evaluate it according to the rules you provide. This process is summarized in the flowchart below:
A few points of note concerning inclusion/exclusion rules:
Path names are first checked for inclusion, then exclusion.
A path name has to match only one from the set of inclusion rules. Each such rule is applied to the path in sequence until a match is found or there are no more rules.
The rules are strings and matched from the beginning of the pathname. The proxy does not analyze them in detail or produce complex internal representations.
Query parameters are supported (but be careful, you can’t really count on a query parameter to have a set position!).
If a path falls outside of the scope of your inclusion rules or an exclusion rule applies to it, it will be greyed out in the page list and the text “Excluded by rule” will be visible next to it.
Paths that are excluded by rule can’t be included using the context menu. You need to edit your rules if they gobble a path that you want to include.
Manual page exclusions overwrite all other inclusion rules.
NOTE: If all pages are excluded on a project, crawls cannot be started, even if the currently active rules would allow for the inclusion of some, as-of-yet undiscovered page. In this case, crawls will exit after 0 pages visited. You have to ensure an entry point: that at least one of the known pages is in an included state. Otherwise, the crawler can’t set its foot in the door.
Though it may seem nonsensical to exclude every single URL on a project, we note this unusal case because it can come about from inadvertent use of inclusion rules.
Consider, for example, that if you set /en/ as the sole “Include only” rule on your project, but no page starting with /en/ is in the page list, then not a single valid entry point is provided to the crawler.