Crawl Analyzer
After using the Crawl Wizard tool, and running a Wordcount (Discovery) or a Content extraction (Scan), you can check its results under the List section by either downloading the .log file, or using the Crawl log visualization filter.
When you click on the filter button, a new window will pop up, where you can narrow down the results of the log.
Crawl status
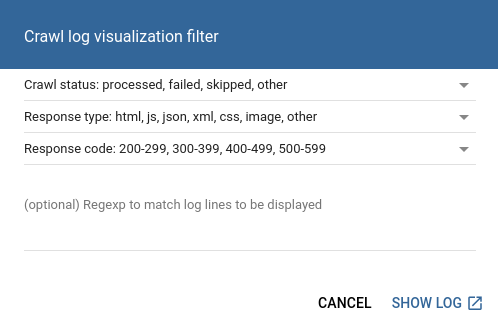
Processed: The page was successfully added to the pages list, the crawler was able to process it.
Skipped: In this case, the Proxy could not process the page, because of its content-type, or because of the configuration of the collectible resources in Crawl wizard. There are four main reasons behind this status:
No content type, page collection is disabled: The crawler hadn’t received a content-type before, and also the collection of new HTML pages is disabled.
HTML page, page collection is disabled: The content-type is text/html, but the collection of new HTML pages is disabled.
Not HTML page, resource collection is disabled: The URL points to a resource (e.g. the content-type is text/javascript or text/css), but the collection of resources is disabled.
Content with type < content-type > is not processed during this crawl: The content-type header designates an unprocessable type, for example if the header is proprietary (such as “application/example-script”), or it is an unsupported content-type, for example text/plain.
Failed: The proxy was not able to process the content, you can see below the list of the reasons behind this status:
Path is externalized: The page is externalized
Request sending failed: The crawler wasn’t able to send a GET request
Content is not an HTML page: The content is not HTML, the crawler wasn’t able process it
Not processable: The crawler wasn’t able process the given content-type
Too large, size: < size of content >, limit: 1048576: Files above 1.5 MB are not handled
Parsing error: Invalid script, or HTML format for example
Proxy request failed, Response not processable, Response processing was aborted, Skipped because processing failed: Error during processing. Sometimes it is not quite obvious at first glance why the crawler failed, but in this case we can check our logs for you
Response type
You can also filter the log results by content-types, for example, you can select different resource types, like CSS, JS, images etc.
Response code
With this filter you can narrow down the log list by HTTP status codes:
1xx (Informational): The request was received, continuing process
2xx (Successful): The request was successfully received, understood, and accepted
3xx (Redirection): Further action needs to be taken in order to complete the request
4xx (Client Error): The request contains bad syntax or cannot be fulfilled
5xx (Server Error): The server failed to fulfill an apparently valid request
Regexp
Inserting here links or other texts, will be treated as strings, but you can specify java/util/Pattern regular expressions as well.
You can test your regex here.